Como criar um sistema estéreo incorporado e personalizado para percepção de profundidade

Há várias opções de sensores 3D para o desenvolvimento de sistemas de percepção de profundidade, incluindo visão estéreo com câmeras, sensores lidar e de tempo de voo. Cada opção tem seus pontos positivos e negativos. Um sistema estéreo é normalmente de baixo custo, robusto o suficiente para uso externo e pode fornecer uma nuvem de ponto de cor em alta resolução.
Há vários sistemas estéreo, prontos para uso, disponíveis no mercado atualmente. Dependendo de fatores como precisão, linha de base, campo de visão e resolução, há momentos em que os engenheiros do sistema precisam construir um sistema personalizado para atender aos requisitos específicos da aplicação.
Neste artigo, primeiro descrevemos as principais partes de um sistema de visão estéreo e, em seguida, fornecemos instruções sobre como fazer sua própria câmera estéreo personalizada, usando componentes de hardware prontos para uso e software de código aberto. Como essa configuração se concentra na incorporação, ela calculará um mapa de profundidade de qualquer cena em tempo real, sem a necessidade de um computador host. Em um artigo separado, discutimos como construir um sistema estéreo personalizado para usar com um computador host, quando o espaço for menos restrito.
Outra aplicação que pode se beneficiar muito de tal sistema de processamento integrado é a detecção de objetos. Com o avanço no aprendizado profundo, tornou-se relativamente fácil adicionar detecção de objetos a aplicações, mas a necessidade de recursos de GPU dedicados a torna restritiva para muitos usuários. Neste artigo, também discutiremos como adicionar aprendizado profundo à sua aplicação de visão estéreo sem a necessidade do uso de GPUs caras. Dividimos o código de exemplo e as seções deste artigo em visão estéreo e aprendizado profundo. Dessa forma, se seu aplicativo não exigir aprendizado profundo, sinta-se à vontade para pular as seções desse assunto.
Panorama da visão estéreo
A visão estéreo é a extração de informações 3D de imagens digitais, comparando as informações em uma cena de dois pontos de vista. As posições relativas de um objeto em dois planos de imagem fornecem informações sobre a profundidade do objeto a partir da câmera.
Um panorama de um sistema de visão estéreo é mostrada na Figura 1 e consiste nas seguintes etapas principais:
- Calibração: A calibração da câmera refere-se tanto ao intrínseco quanto ao extrínseco A calibração intrínseca determina o centro da imagem, a distância focal e os parâmetros de distorção, enquanto a calibração extrínseca determina as posições 3D das câmeras. Esta é uma etapa crucial em muitos aplicativos de visão para computadores, especialmente quando são necessárias informações métricas sobre a cena, como profundidade. Discutiremos a etapa de calibração em detalhes na Seção 5, abaixo.
- Retificação: A retificação estéreo refere-se ao processo de reprojetar planos de imagem em um plano comum, em paralelo à linha entre os centros da câmera. Após a retificação, os pontos correspondentes ficam na mesma linha, o que reduz muito o custo e a ambiguidade da correspondência. Esta etapa é feita no código fornecido para criar seu próprio sistema.
- Correspondência estéreo: Refere-se ao processo de correspondência de pixels entre as imagens esquerda e direita, o que gera imagens de disparidade. O algoritmo Semi-Global Matching (SGM) será usado no código fornecido para construir seu próprio sistema.
- Triangulação: Triangulação refere-se ao processo de determinação de um ponto no espaço 3D, dada sua projeção nas duas imagens. A imagem de disparidade será convertida em uma nuvem de pontos 3D.
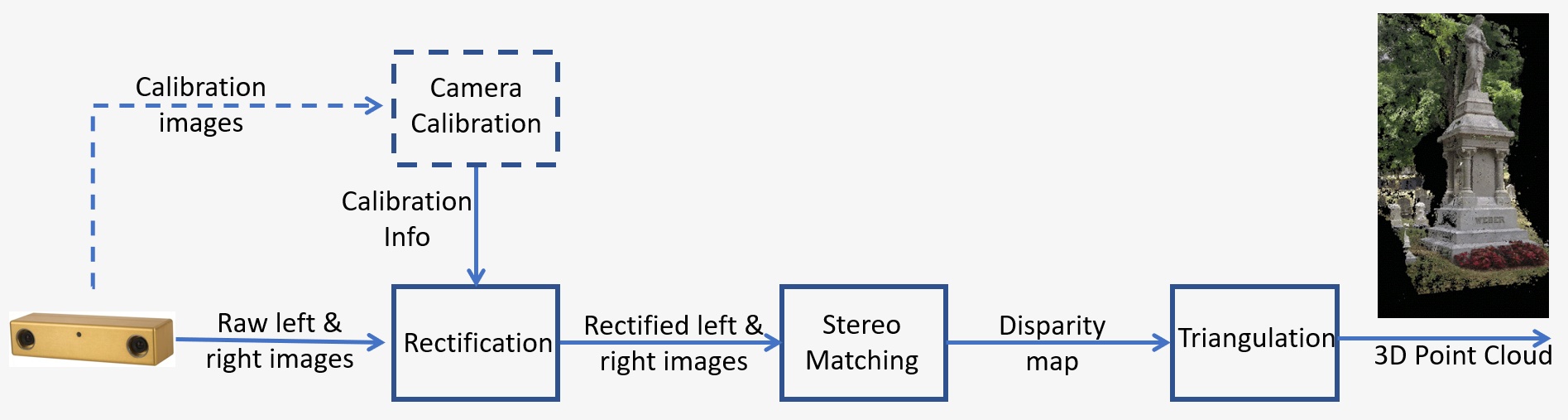
Figura 1: Panorama de um sistema de visão estéreo
Visão geral do aprendizado profundo
O aprendizado profundo é um subcampo do machine learning que lida com algoritmos baseados na estrutura e função do cérebro. Ele tenta imitar a capacidade de aprendizagem do cérebro humano. Os algoritmos de aprendizagem profunda podem executar operações complexas de forma eficiente, como reconhecimento de objetos, classificação, segmentação etc. Entre outras coisas, o aprendizado profundo permite que as máquinas reconheçam pessoas e objetos nas imagens processadas por elas. A aplicação específica na qual estamos interessados é a detecção de pessoas. Treinar seus próprios algoritmos de aprendizado profundo requer uma grande quantidade de dados de treinamento rotulados, mas os modelos pré-treinados de código aberto facilitam o desenvolvimento desses aplicativos por qualquer pessoa.
O aprendizado profundo também requer GPUs de alto desempenho, mas a solução Quartet para TX2 tem todos os recursos de uma GPU ampla em uma fração do fator de forma e do consumo de energia. Ter os modelos de aprendizado profundo em execução no TX2 proporciona o benefício adicional da mobilidade e pode ser perfeito para robôs móveis, que precisam detectar pessoas e evitá-las.
Exemplo de projeto
Vamos ver um exemplo de design de sistema estéreo. Estes são os requisitos para uma aplicação de robô móvel em um ambiente dinâmico, com objetos em movimento rápido. A cena de interesse tem 2 m de tamanho, a distância das câmeras até a cena é de 3 m e a precisão desejada é de 1 cm a 3 m.
Você pode consultar este artigo para obter mais detalhes sobre a precisão estéreo. O erro de profundidade é dado por: ΔZ=Z²/Bf * Δd, que depende dos seguintes fatores:
- Z é a faixa
- B é a linha de base
- f é a distância focal em pixels, que está relacionada ao campo de visão da câmera e à resolução da imagem
Há várias opções de projeto que podem atender a esses requisitos. Com base no tamanho da cena e nos requisitos de distância acima, podemos determinar a distância focal da lente para um sensor específico. Juntamente com a linha de base, podemos usar a fórmula acima para calcular o erro de profundidade esperado a 3 m, para verificar se atende ao requisito de precisão.
Duas opções são mostradas na Figura 2, usando câmeras de resolução mais baixa com uma linha de base mais longa ou câmeras de resolução mais alta com uma mais curta. A primeira opção é uma câmera maior, mas com menor necessidade computacional, enquanto a segunda opção é uma câmera mais compacta, mas com maior necessidade computacional. Para esta aplicação, escolhemos a segunda opção, pois um tamanho compacto é mais desejável para o robô móvel e podemos usar o Quartet Embedded Solution for TX2, que tem uma avançada GPU integrada para lidar com as necessidades de processamento.

Figura 2: Opções de projeto de sistema estéreo para um exemplo de aplicação
Requisitos de hardware
Para este exemplo, montamos duas câmeras de 1,6 MP com nível de placa Blackfly S, usando o sensor de obturador global IMX273 Sony Pregius em uma barra impressa em 3D na linha de base de 12 cm. Ambas as câmeras têm lentes similares de 6 mm montadas em S. As câmeras se conectam à placa da transportadora customizada Quartet Embedded Solution for TX2, usando dois cabos FPC. Para sincronizar as câmeras esquerda e direita para capturar imagens ao mesmo tempo, um cabo de sincronização é feito para conectar as duas câmeras. A Figura 3 mostra as visualizações frontal e traseira do nosso sistema estéreo incorporado e personalizado.

Figura 3: Visualizações frontal e traseira do nosso sistema estéreo incorporado e personalizado
A tabela a seguir lista todos os componentes de hardware:
|
Peça |
Descrição |
Quantidade |
Link |
|
ACC-01-6005 |
Suporte Quarteto com Módulo TX2 de 8 GB |
1 |
https://www.flir.com/products/quartet-embedded-solution-for-tx2/ |
|
BFS-U3-16S2C-BD2 |
1,6 MP, 226 FPS, Sony IMX273, Cor |
2 |
|
|
ACC-01-5009 |
Montagem em S e filtro IV para câmeras BFS em cores por placa |
2 |
|
|
BW3M60B-1000 |
Lente com montagem em S de 6 mm |
|
http://www.boowon.co.kr/site/ |
|
ACC-01-2401 |
Cabo FPC 15 cm para Blackfly S ao nível da placa |
2 |
https://www.flir.com/products/15-cm-fpc-cable-for-board-level-blackfly-s/ |
|
XHG302 |
Dissipador de calor ativo NVIDIA® Jetson™ TX2/TX2 de 4GB/TX2i |
1 |
https://connecttech.com/product/nvidia-jetson-tx2-tx1-active-heat-sink/ |
|
Cabo de sincronização (providencie o seu) |
1 |
||
|
Barra de montagem (providencie a sua) |
1 |
Ambas as lentes devem ser ajustadas para focalizar as câmeras na faixa de distâncias que sua aplicação requer. Aperte o parafuso (no círculo vermelho na Figura 4) em cada lente, para manter o foco.

Figura 4: Visualização lateral do nosso sistema estéreo, mostrando o parafuso da lente
Requisitos de software
a. Spinnaker
O Teledyne FLIR Spinnaker SDK vem pré-instalado em suas Quartet Embedded Solutions for TX2. O Spinnaker deve se comunicar com as câmeras.
b. OpenCV 4.5.2 com suporte CUDA
O OpenCV versão 4.5.1 ou mais recente é necessário para SGM, o algoritmo de correspondência estéreo que estamos usando. Baixe o arquivo zip que contém o código deste artigo e descompacte-o na pasta StereoDepth. O script para instalar o OpenCV é OpenCVInstaller.sh. Digite os seguintes comandos em um terminal:
- cd ~/StereoDepth
- chmod +x OpenCVInstaller.sh
- ./OpenCVInstaller.sh
O instalador pedirá que você insira sua senha de administrador. O instalador começará a instalar o OpenCV 4.5.2. Pode levar algumas horas para baixar e criar o OpenCV.
c. Jetson-inference (se o aprendizado profundo for necessário)
Jetson-inference é uma biblioteca de código aberto da NVIDIA que pode ser usada para aprendizado profundo acelerado por GPU em dispositivos Jetson, como o TX2. A biblioteca faz uso do TensorRT SDK, que facilita a inferência de alto desempenho em GPUs NVIDIA. O Jetson-inference fornece ao usuário uma série de modelos de aprendizado profundo pré-treinados e prontos para uso, e o código para implantar esses modelos usando o TensorRT. Para instalar o Jetson-inference, digite os seguintes comandos em um terminal:
- cd ~/StereoDepth
- chmod +x InferenceInstaller.sh
- ./InferenceInstaller.sh
Calibração
O código para capturar imagens estéreo e calibrá-las pode ser encontrado na pasta “Calibration”. Use a GUI SpinView para identificar os números de série das câmeras esquerda e direita. Para nossas configurações, a câmera direita é a câmera principal e a câmera esquerda, a secundária. Copie os números de série das câmeras principal e secundária para o arquivo grabStereoImages.cpp, linhas 60 e 61. Crie o executável usando os seguintes comandos em um terminal:
- cd ~/StereoDepth/Calibration
- mkdir build
- mkdir -p images/{left, right}
- cd build
- cmake ..
- make
Imprima o padrão quadriculado neste link e anexe-o a uma superfície plana, para usar como alvo de calibração. Para obter melhores resultados durante a calibração, no SpinView, defina Exposure Auto (Exposição automática) como Off (Desativada) e ajuste a exposição para que o padrão quadriculado fique claro e os quadrados brancos não fiquem expostos em excesso, como mostrado na Figura 5. Depois que as imagens de calibração forem coletadas, o ganho e a exposição podem ser definidos como automáticos no SpinView.
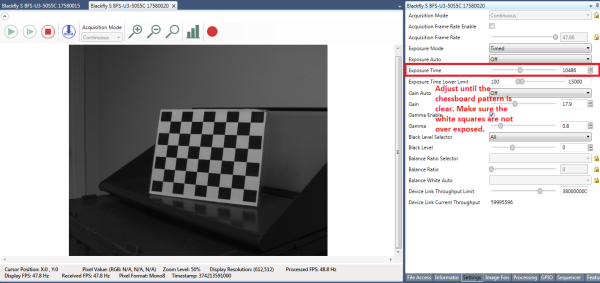
Figura 5: Configurações da GUI SpinView
Para começar a coletar as imagens, digite
- ./grabStereoImages
O código deve começar a coletar imagens a cerca de 1 quadro/segundo. As imagens à esquerda são armazenadas na pasta images/left e as imagens à direita são armazenadas na pasta images/right. Mova o alvo para que ele apareça em todos os cantos da imagem. Você pode girar o alvo, capturar imagens de perto e de longe. Por definição, o programa captura 100 pares de imagens, mas pode ser alterado com um argumento de linha de comando:
- ./grabStereoImages 20
Isso coletará apenas 20 pares de imagens. Observe que isso apagará todas as imagens gravadas anteriormente nas pastas. Algumas imagens de calibração de amostra são mostradas na Figura 6.

Figura 6: Amostras de imagens de calibração
Após coletar as imagens, execute o código Python de calibração digitando:
- cd ~/StereoDepth/Calibration
- python cameraCalibration.py
Isso gerará 2 arquivos, chamados “intrinsics.yml” e “extrinsics.yml”, que contêm os parâmetros intrínsecos e extrínsecos do sistema estéreo. O código assume o tamanho do quadrado de 30 mm do padrão quadriculado por definição, mas pode ser editado se necessário. No final da calibração, o erro RMS será exibido para indicar a qualidade da calibração. O erro típico de RMS para uma boa calibração deve estar abaixo de 0,5 pixel.
Mapa de profundidade em tempo real
O código para calcular a disparidade em tempo real está na pasta “Depth”. Copie os números de série das câmeras para o arquivo live_disparity.cpp, linhas 230 e 231. Crie o executável usando os seguintes comandos em um terminal:
- cd ~/StereoDepth/Depth
- mkdir build
- cd build
- cmake ..
- make
Copie os arquivos “intrinsics.yml” e “extrinsics.yml”, obtidos na etapa de calibração, para esta pasta. Para executar a demonstração do mapa de profundidade em tempo real, digite
- ./live_disparity
Isso exibiria a imagem da câmera esquerda (imagem bruta sem retificação) e o mapa de profundidade (nosso arquivo final). Alguns exemplos de arquivos são mostrados na Figura 7. A distância da câmera é codificada por cores, de acordo com a legenda à direita do mapa de profundidade. A região preta no mapa de profundidade significa que nenhum dado de disparidade foi encontrado nessa região. Graças à GPU NVIDIA Jetson TX2, é possível executar até 5 quadros/segundo, a uma resolução de 1440 × 1080, e até 13 quadros/segundo a uma resolução de 720 × 540.
Para ver a profundidade em um ponto específico, clique nesse ponto no mapa de profundidade e a profundidade será exibida, conforme mostrado no último exemplo na Figura 7.

Figura 7: Amostra de imagens da câmera esquerda e mapa de profundidade correspondente. O mapa de profundidade inferior também mostra a profundidade em um ponto específico.
Detecção de pessoas
Usamos o DetectNet, fornecido pela Jetson-inference, para detectar humanos em um quadro de imagem. O DetectNet vem com opções para selecionar a arquitetura do modelo de aprendizado profundo para detecção de objetos. Usamos a arquitetura Single Shot Detection (Detecção de Disparo Único, SSD) com um backbone MobileNetV2 para otimizar a velocidade e a precisão. Ao executar a demonstração pela primeira vez, o TensorRT cria um mecanismo serializado para otimizar ainda mais a velocidade de inferência, que pode levar alguns minutos para ser concluída. Esse mecanismo é salvo automaticamente em arquivos para outras execuções. A arquitetura utilizada é bastante eficiente e pode-se esperar aproximadamente 50 fps para a execução do módulo de detecção. O código para a capacidade de detecção de pessoas, juntamente com a profundidade estéreo em tempo real, está na pasta “DepthAndDetection”. Copie os números de série das câmeras para o arquivo live_disparity.cpp, nas linhas 271 e 272. Crie o arquivo executável usando os seguintes comandos em um terminal:
- cd ~/StereoDepth/DepthAndDetection
mkdir
buildcd
buildcmake ..
make
Copie os arquivos “intrinsics.yml” e “extrinsics.yml” obtidos na etapa de calibração para essa pasta. Para executar a demonstração do mapa de profundidade em tempo real, digite
- ./live_disparity
Serão exibidas duas janelas com as imagens coloridas retificadas à esquerda e o mapa de profundidade. O mapa de profundidade é codificado por cores para uma melhor visualização. Ambas as janelas têm caixas delimitadoras ao redor das pessoas no quadro e mostram a distância média da pessoa em relação à câmera. Com processamento estéreo e inferência de aprendizado profundo, a demonstração é executada em torno de 4 fps a uma resolução de 1440 × 1080 e até 11,5 fps para uma resolução de 720 × 540.

Figura 1: Exemplos de imagens da câmera à esquerda e o mapa de profundidade correspondente. Todas as imagens mostram a pessoa detectada e a distância da pessoa em relação à câmera.
O algoritmo de detecção de pessoas é capaz de detectar várias pessoas, mesmo em condições desafiadoras, como a oclusão. O código calcula as distâncias para todas as pessoas detectadas na imagem, como mostrado abaixo.

Figura 2: A imagem à esquerda e o mapa de profundidade mostram várias pessoas sendo detectadas e sua distância correspondente em relação à câmera.
Resumo
Usar a visão estéreo para desenvolver uma percepção de profundidade tem as vantagens de funcionar bem ao ar livre, a capacidade de fornecer um mapa de profundidade em alta resolução e de ser muito acessível, com componentes de baixo custo prontos para uso. Dependendo dos requisitos, há vários sistemas estéreo prontos para uso no mercado. Caso seja necessário desenvolver um sistema estéreo embarcado e personalizado, a tarefa fica relativamente simplificada com as instruções fornecidas aqui.
Artigos Relacionados
-
Sistemas integrados
Como criar um sistema estéreo incorporado e personalizado para percepção de profundidade
Saiba mais -
 Sistemas integrados
Sistemas integrados
Transmissão de 4 câmeras com placa portadora pequena: Protótipo rápido
Leia a História -
 Sistemas integrados
Sistemas integrados
Guia para a integração de câmeras ao nível de placa
Leia a História